
Mahout介绍
Apache Mahout 是 Apache Software Foundation (ASF) 开发的一个全新的开源项目,其主要目标是创建一些可伸缩的机器学习算法,供开发人员在 Apache 在许可下免费使用。Mahout 包含许多实现,包括集群、分类、CP 和进化程序。此外,通过使用 Apache Hadoop 库,Mahout 可以有效地扩展到云中。2012年6月16日,Mahout已经发布0.7版本,支持分布式协同过滤、K-means聚类、bayes分类等功能。
虽然在开源领域中相对较为年轻,但 Mahout 已经提供了大量功能,特别是在集群和 CF 方面。Mahout 的主要特性包括:
- Taste CF。Taste 是 Sean Owen 在 SourceForge 上发起的一个针对 CF 的开源项目,并在 2008 年被赠予 Mahout。
- 一些支持Map-Reduce 的集群实现包括 k-Means、模糊 k-Means、Canopy、Dirichlet 和 Mean-Shift。
- Distributed Naive Bayes 和 Complementary Naive Bayes 分类实现。
- 针对进化编程的分布式适用性功能。
- Matrix 和矢量库。
- 上述算法的示例
实验中发现,Mahout 0.5及以前版本在写文件时存在严重bug,在大数据量的情况下会出现数据丢失,建议使用0.6及以上版本。
kmeans聚类算法
mahout安装及部署
首先需要搭建hadoop环境,然后到mahout官网(http://mahout.apache.org/)上下载mahout-distribution-0.7.tar.gz,这个是已经编译好的包,如果下的是源码包,则需要安装maven来编译。
其次,需要设置环境变量sudo vi /etc/profile例如:
export HADOOP_HOME=/home/guang/Desktop/tools/hadoop-0.20.2
export HADOOP_CONF_DIR=/home/guang/Desktop/tools/hadoop-0.20.2/conf
export MAHOUT_HOME=/home/guang/Desktop/tools/mahout-distribution-0.7
export PATH=$HADOOP_HOME/bin:$MAHOUT_HOME/bin:$PATH最后,测试hadoop,出现以下内容则hadoop能够正常运行:
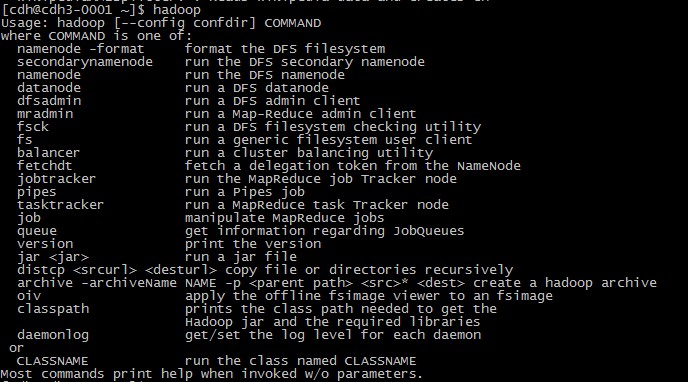
测试mahout,出现以下内容则hadoop能够正常运行:
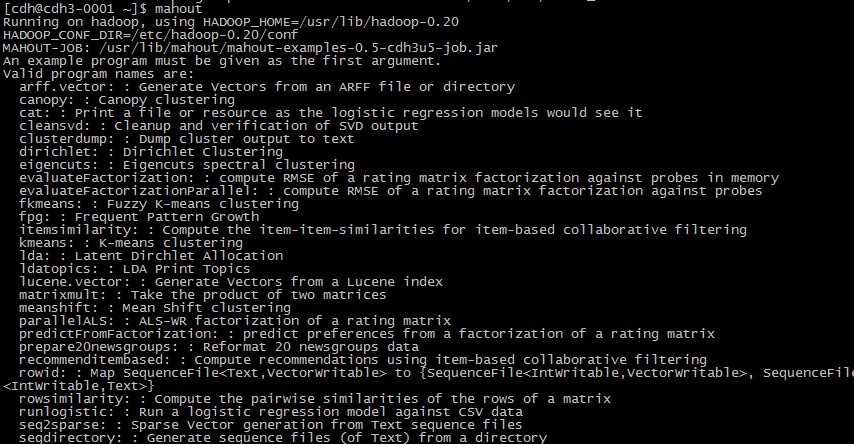
其中列出了mahout可以运行的算法及简介。至此,mahout部署完成。
mahout kmeans文本聚类
数据预处理
mahout下处理的文件必须是SequenceFile格式的,所以需要把txtfile转换成sequenceFile。SequenceFile是hadoop中的一个类,允许我们向文件中写入二进制的键值对。mahout中提供了一种将指定文件下的文件转换成sequenceFile的方式。
- 首先将需要聚类的文本数据进行分词,去停用词等处理,然后将其存放一个文件夹clusterdata下,其中每个文件为一个样本的文本数据,然后将其上传至hdfs上:
hadoop fs -put clusterdata(本地路径) clusterdata(hdfs路径)- 使用mahout seqdirectory命令将文件转化为sequencefile格式
mahout seqdirectory -i clusterdata -o clusterdata_seq- 使用mahout seq2sparse命令将sequencefile数据进行局域Lucene工具的向量化,其参数可以使用mahout seq2sparse -h查看
mahout seq2sparse --input clusterdata_seq/ --output clusterdata_vectors --analyzerName org.apache.lucene.analysis.WhitespaceAnalyzer --chunkSize 200 --weight tfidf --minSupport 2 --minDF 2 --maxDFPercent 90 --maxNGramSize 1 --minLLR 50 --sequentialAccessVector这时,可以在weibo_vectors文件夹下看到一下目录:
- df-count 目录:保存着文本的频率信息
- tf-vectors 目录:保存着以 TF 作为权值的文本向量
- tfidf-vectors 目录:保存着以 TFIDF 作为权值的文本向量
- tokenized-documents 目录:保存着分词过后的文本信息
- wordcount 目录:保存着全局的词汇出现的次数
- dictionary.file-0 目录:保存着这些文本的词汇表
- frequcency-file-0 目录 : 保存着词汇表对应的频率信息。
可以选择tf-vectors或者tfidf-vectors作为输入进行聚类操作。
kmeans聚类
mahout kmeans的主要参数
mahout kmeans
-i <input vectors directory>
-c <input clusters directory>
-o <output working directory>
-k <optional number of initial clusters to sample from input vectors>
-dm <DistanceMeasure>
-x <maximum number of iterations>
-cd <optional convergence delta. Default is 0.5>
-ow <overwrite output directory if present>
-cl <run clustering after the iterations have taken place if present>
-xm <execution method: sequential or mapreduce>注意: 当-k被指定的时候,-c目录下的所有聚类都将被重写,将从输入的数据向量中随机抽取-k个点作为初始聚类的中心。其中-cl参数很重要,用来在循环后生成簇,为每个数据点标记其簇名。
mahout kmeans -i clusterdata_vectors/tfidf-vectors -o clusterdata_output -c cluster_data_initial -k 10 -x 20 -cl结果文件解析
运行完kmeans命令后,将在clusterdata_output中的到clusteredPoints,clusters-N,data
- clusteredPoints:结果的key-value类型是(IntWritable,WeightedVectorWritable),用seqdumper命令查看,key为簇名,value为向量
- clusters-N:是第N次聚类的结果,其中n为某类的样本数目,c为各类各属性的中心,r为各类属性的半径。 clusters-N结果类型是(Text,Cluster)
- data:存放的是原始数据,这个文件夹下的文件可以用mahout vectordump来读取,原始数据是向量形式的,其它的都只能用mahout seqdumper来读取,向量文件也可以用mahout seqdumper来读取,只是用vectordump读取出来的是数字结果,没有对应的key,用seqdumper读出来的可以看到key,即对应的url,而value读出来的是一个类描述,而不是数组向量
根据以上信息,mahout提供了clusterdump将每一类的点列出来,如下:
mahout clusterdump --input clusterdata_output/clusters-10 --pointsDir clusterdata_output/clusteredPoints --output /home/test/output(本地目录)此外,mahout还提供了命令用来得到属于每个簇的概率最高的词汇,命令如下
mahout clusterdump –dt sequencefile -d dictionary.file-* -i clusters-*-final –b 0 –n 10其中,-dt参数为指定字典文件的类型,可以为text或sequencefile,-n用来指定输出每个簇的前n个概率最高的词汇,也可以使用-o命令将结果输出到本地。